Worker pools»
Info
This feature is only available on the Starter+ plan and above. Please check out our pricing page for more information.
By default, Spacelift uses a public worker pool hosted and operated by us. While this works for many users, you may have special requirements regarding infrastructure, security, or compliance that aren't served by the public worker pool. Spacelift also supports private worker pools, which you can use to host the workers that execute Spacelift workflows on your end.
To enjoy the maximum level of flexibility and security with a private worker pool, temporary run state is encrypted end-to-end, so only the workers in your worker pool can look inside it. We use asymmetric encryption to achieve this and only you have access to the private key.
Tip
A worker is a logical entity that processes a single run at a time. As a result, your number of workers is equal to your maximum concurrency.
Typically, a virtual server (AWS EC2 or Azure/GCP VM) hosts a single worker to keep things simple and avoid coordination and resource management overhead.
Containerized workers can share the same virtual server because the management is handled by the orchestrator.
Shared responsibility model»
Spacelift shares the responsibility for overall worker maintenance with you. How you use public and private workers depends on the level of configuration your organization needs and the level of responsibility you can take on. There are some worker permissions you can only manage with private workers.
In your infrastructure, responsibility is broken down into chunks:
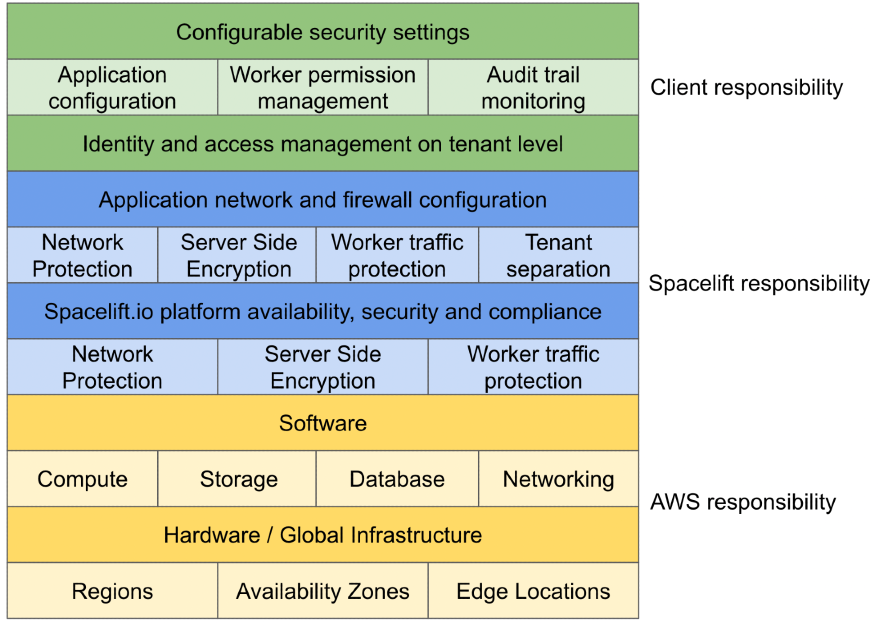
Public vs private worker comparison»
Private workers offer more customization options, but your organization is responsible for maintaining them by configuring compute resources, network access rules, and worker updates. With public workers, maintenance falls on Spacelift's side.
| Private workers | Public workers |
|---|---|
| Offer more customization but require more responsibility from client | Offer less customization but require less responsibility |
| Deployed in client infrastructure | Deployed in Spacelift's infrastructure |
| Assumes client's cloud provider IAM role | Needs trust relations between Spacelift's cloud provider and client's |
| All actions taken from client's infrastructure | All actions taken from Spacelift's infrastructure |
| Private or public Docker repository | Only public Docker repository |
Setting up»
1. Generate worker private key»
We use asymmetric encryption to ensure that any temporary run state can only be accessed by workers in a given worker pool. To support this, you need to:
- Generate a private key that can be used for this purpose.
- Use the private key to create a certificate signing request (CSR) to give to Spacelift.
Spacelift will generate a certificate for you so workers can authenticate with the Spacelift backend. The following command will generate the key and CSR:
1 | |
Store your private key
Save your spacelift.key file (private key) in a secure location. You’ll need it when launching workers in your worker pool.
You can set up your worker pool from the Spacelift UI on the Manage Organization > Worker Pools tab. You can also create it programmatically using the spacelift_worker_pool resource type within the Spacelift Terraform provider.
2. Add worker pool entity»
- Navigate to Manage Organization > Worker Pools.
- Click Create worker pool.
- Enter worker pool details:
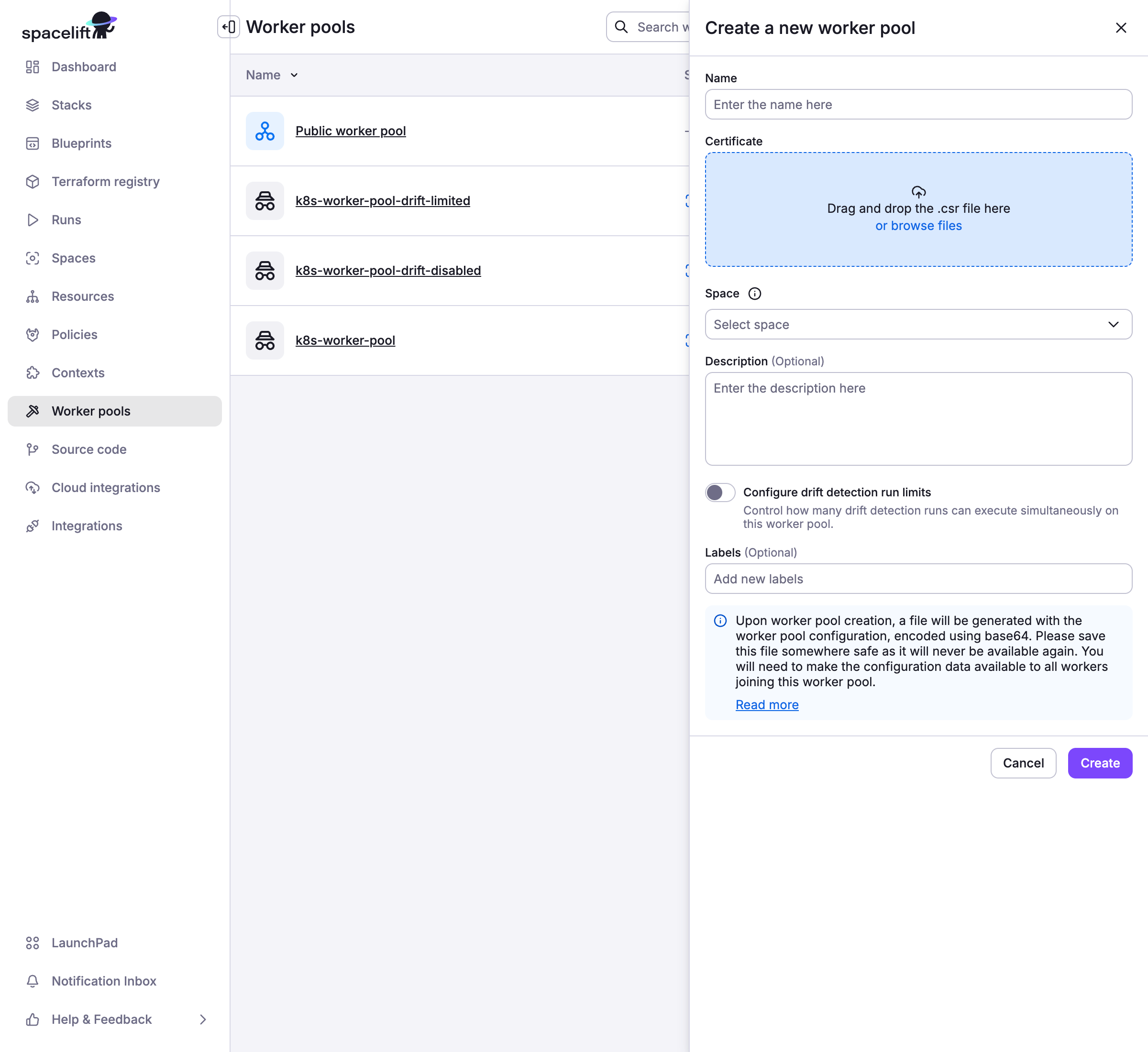
- Name: Enter a unique, descriptive name for your worker pool.
- Certificate: Drag and drop or browse and upload the
spacelift.csrfile you generated. - Space: Select the space to create the worker pool in.
- Description (optional): Enter a (markdown-supported) description of the worker pool.
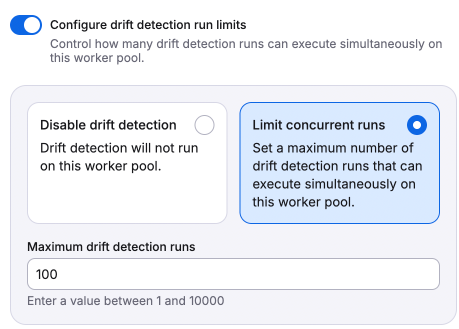
- Configure drift detection run limits: Enable to either disable drift detection entirely or set a limit on concurrent drift detection runs that can execute on the worker pool.
- Labels: Add labels to help sort and filter your worker pools.
- Click Create.
When the worker pool is created, you'll receive a base64-encoded Spacelift worker pool token containing configuration for your worker pool launchers and the certificate generated from the CSR.
Store your worker pool token
Save your Spacelift token in a secure location. You'll need it when launching the worker pool.
Adding entity in OpenTofu/Terraform»
Plaintext secrets
Spacelift does not recommend this method because it will store your private key in plaintext in the OpenTofu/Terraform state file. Only use this method if absolutely necessary.
We recommend trying a more secure process, such as: storing credentials in AWS/GCP/Azure secrets managers, configuring worker instances to fetch them at boot, and setting SPACELIFT_TOKEN and SPACELIFT_POOL_PRIVATE_KEY from the fetched values.
This example shows how to implement a way to reference the private key when configuring worker pools via OpenTofu/Terraform.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | |
Then, if you ever need to reference the private key, use tls_private_key.this.
3. Launch worker pool»
You can run workers using Docker or inside a Kubernetes cluster:
- Set up Docker-based workers.
- Set up Kubernetes workers.
Configuration options»
A number of configuration variables are available to customize how your worker pool launcher behaves. Some are shared and some are specific to Docker-based workers.
Shared options»
| Configuration variable | Details |
|---|---|
SPACELIFT_MASK_ENVS |
Comma-delimited list of allowlisted environment variables that are passed to the workers but should never appear in the logs. |
SPACELIFT_SENSITIVE_OUTPUT_UPLOAD_ENABLED |
If set to true, the launcher will upload sensitive run outputs to the Spacelift backend. Required if you want to use sensitive outputs for stack dependencies. |
SPACELIFT_RUN_LOGS_ON_STANDARD_OUTPUT_ENABLED |
If set to true, the launcher will write run logs to standard output in the same structured format as the rest of the logs. Some useful fields are run_ulid, stack_id, ts, and msg. You can easily manage run logs and ship them anywhere you want. |
SPACELIFT_LAUNCHER_RUN_INITIALIZATION_POLICY |
File that contains the run initialization policy that will be parsed/used. If the run initialized policy cannot be validated at startup, the worker pool will exit with an appropriate error. See the Kubernetes-specific configuration section for more information. |
SPACELIFT_LAUNCHER_LOGS_TIMEOUT |
Custom timeout (the default is 7 minutes) for killing jobs not producing any logs. This is a duration flag, expecting a duration-formatted value, e.g. 1000s. See the Kubernetes-specific configuration section for more information. |
SPACELIFT_LAUNCHER_RUN_TIMEOUT |
Custom maximum run time (default is 70 minutes). This is a duration flag, expecting a duration-formatted value, e.g. 120m. See the Kubernetes-specific configuration section for more information. |
SPACELIFT_DEBUG |
If set to true, this will output the exact commands Spacelift runs to the worker logs. |
SPACELIFT_WORKER_COMMS_PROTOCOL |
Transport the worker uses to receive work from Spacelift: mqtt (default) or poll (HTTP long-poll). See Worker communication. |
SPACELIFT_WORKER_COMMS_URL |
Base URL of the Spacelift server the worker polls. Required when SPACELIFT_WORKER_COMMS_PROTOCOL is poll. See Worker communication for the value to use. |
SPACELIFT_WORKER_POLL_LONG_TIMEOUT |
How long an idle poll-mode worker asks the server to hold a request open. Defaults to 60s, minimum 5s. See Worker communication. |
Warning
Server-side initialization policies are being deprecated. In comparisin, this policy is a worker-side initialization policy and can be set by using the SPACELIFT_LAUNCHER_RUN_INITIALIZATION_POLICY flag.
For a limited time, Spacelift will be running both types of initialization policy checks. We're planning to move the pre-flight checks to the worker node, thus allowing customers to block suspicious looking jobs on their end.
Docker-only options»
| Configuration variable | Details |
|---|---|
SPACELIFT_DOCKER_CONFIG_DIR |
If set, the value of this variable will point to the directory containing Docker configuration, which includes credentials for private Docker registries. Private workers can populate this directory by executing docker login before the launcher process is started. |
SPACELIFT_WHITELIST_ENVS |
Comma-delimited list of environment variables to pass from the launcher's environment to the workers' environment. They can be prefixed with ro_ to only be included in read-only runs or wo_ to only be included in write-only runs. |
SPACELIFT_WORKER_EXTRA_MOUNTS |
Additional files or directories to be mounted to the launched worker Docker containers during either read or write runs, as a comma-separated list of mounts in the form of /host/path:/container/path. |
SPACELIFT_WORKER_NETWORK |
Network ID/name to connect the launched worker containers. Defaults to bridge. |
SPACELIFT_WORKER_RUNTIME |
Runtime to use for worker container. You can check which runtimes are available on your system with docker info. |
SPACELIFT_WORKER_RO_EXTRA_MOUNTS |
Additional directories to be mounted to the worker Docker container during read-only runs, as a comma separated list of mounts in the form of /host/path:/container/path. |
SPACELIFT_WORKER_WO_EXTRA_MOUNTS |
Additional directories to be mounted to the worker Docker container during write-only runs, as a comma separated list of mounts in the form of /host/path:/container/path. |
SPACELIFT_DEFAULT_RUNNER_IMAGE |
If set, this will override the default runner image used for non-Ansible runs. The default is public.ecr.aws/spacelift/runner-terraform:latest. This will not override a custom runner image on a stack and will only take effect if no custom image is set. |
SPACELIFT_DEFAULT_ANSIBLE_RUNNER_IMAGE |
If set, this will override the default runner image used for Ansible runs. The default is public.ecr.aws/spacelift/runner-ansible:latest. This will not override a custom runner image on a stack and will only take effect if no custom image is set. |
Kubernetes-specific configuration»
There is more detailed information available in the Kubernetes workers documentation for certain configuration options:
- Set up initialization policies.
- Configure timeouts.
Passing metadata tags»
Passing custom metadata tags is currently only supported for Docker-based workers. Kubernetes workers send through some metadata, including the name of the Worker resource in Kubernetes along with the version of the controller used to create the worker, but do not support user-provided custom metadata.
When the launcher from a worker pool is registering with the mothership, you can send along some tags that will allow you to uniquely identify the process/machine for the purpose of draining or debugging. Any environment variables using SPACELIFT_METADATA_ prefix will be passed on. For example, if you're running Spacelift workers in EC2, you can do the following just before you execute the launcher binary:
1 | |
This will set your EC2 instance ID as instance_id tag in your worker.
Provider caching»
You can cache providers on your private workers to speed up your runs because your workers don't need to download providers from the internet every time a run is executed. Provider caching is supported in Spacelift with a little configuration on the worker side:
- On the worker: Export the
SPACELIFT_WORKER_EXTRA_MOUNTSvariable with the path to the directory where the providers will be stored. - In the stack: Where you want to enable provider caching, set the
TF_PLUGIN_CACHE_DIRenvironment variable to the path you specified in theSPACELIFT_WORKER_EXTRA_MOUNTSvariable.
The SPACELIFT_WORKER_EXTRA_MOUNTS directory on the host should use shared storage that is accessible by all workers in the pool. This can be a shared filesystem, a network drive, or a cloud storage service. If you choose not to use a shared storage solution, you might run into an issue where the plan phase succeeds but the apply phase fails due to the provider cache not being available.
To avoid this, you can run tofu init (if using OpenTofu) or terraform init (if using Terraform) as a before-apply hook, which will populate the cache on that node. Once the cache is populated, re-initialization should be quick.
Worker communication»
Private workers receive work from Spacelift (job assignments, kill and stop signals) over one of two transports:
- MQTT (default) — the worker maintains an MQTT connection to a broker. On SaaS this is AWS IoT Core; on Self-Hosted it is either AWS IoT Core or the built-in broker.
- HTTP long-poll — the worker repeatedly opens an outbound HTTPS request to the Spacelift server, which holds it open until there is work to deliver.
With HTTP long-poll, a worker only needs outbound HTTPS (port 443) to your Spacelift server. It does not need any connectivity to an MQTT broker or to the AWS IoT Core endpoints, which simplifies the firewall and egress rules for your workers. See Network security for the full endpoint list per transport.
MQTT is being retired
Worker communication via AWS IoT Core (worker-iot.spacelift.io) is being sunset at the end of 2026. HTTP long-poll is its replacement and the recommended transport going forward. We recommend switching your private workers to the poll transport ahead of that date.
Enabling HTTP long-poll»
The transport is selected entirely on the worker. There is no account- or server-side setting to change — a worker registers its transport automatically when it connects. Set the following environment variables before starting the launcher:
1 2 | |
SPACELIFT_WORKER_COMMS_PROTOCOL: set topollto use HTTP long-poll instead of the defaultmqtt.-
SPACELIFT_WORKER_COMMS_URL: the base URL of the Spacelift server — the shared Spacelift domain, not your account-specific subdomain.Use
https://app.spacelift.io(not<your account name>.app.spacelift.io); for US-region accounts usehttps://app.us.spacelift.io. -
SPACELIFT_WORKER_POLL_LONG_TIMEOUT(optional): how long an idle worker asks the server to hold a request open. Defaults to60s(minimum5s). Only lower this if a proxy or load balancer between your workers and Spacelift enforces a shorter idle timeout.
These variables apply to Docker-based workers. Kubernetes workers select the transport through the WorkerPool resource instead — see Worker communication in the Kubernetes workers guide.
Network security»
Private workers need to be able to make outbound connections in order to communicate with Spacelift and access any resources required by your runs. If you have policies in place that require limits on the outbound traffic allowed from your workers, use the following lists as a guide.
Required outbound endpoints»
For your private workers to connect to Spacelift, they must be allowed outbound access to the following AWS services, regardless of where you host the workers (AWS, Azure, or GCP). You can refer to the AWS documentation for AWS IP address ranges.
Upcoming change: downloads.spacelift.io is moving to Cloudflare
After August 31, 2026, downloads.spacelift.io (and downloads.us.spacelift.io) will be served by Cloudflare instead of CloudFront.
If you restrict your workers' outbound traffic by IP, add Cloudflare's IP ranges to your allowlist before then, alongside the existing AWS ranges. If your workers have unrestricted outbound internet access no action is needed.
Give private workers access to:
- The public Elastic Container Registry (if using Spacelift's default runner image).
app.spacelift.io,registry.spacelift.io,<your account name>.app.spacelift.io, anddownloads.spacelift.iowhich point at CloudFront.worker-iot.spacelift.io. This points at the AWS IoT Core endpoints for worker communication via MQTT. Only required when using the MQTT transport, which is being retired at the end of 2026. Workers using the HTTP long-poll transport communicate overapp.spacelift.ioand do not need access to this endpoint.-
US Regional URLs
If your account is in the US region, your workers need access toapp.us.spacelift.io,registry.us.spacelift.io,<your account name>.app.us.spacelift.io,downloads.us.spacelift.io, andworker-iot.us.spacelift.ioinstead.
-
- Amazon S3 for uploading run logs.
Failover
Allow access to the IoT Core and S3 endpoints in both the eu-west-1 and eu-central-1 regions. Typically we use services in eu-west-1, however in the case of a full regional outage of eu-west-1 we would failover to the eu-central-1 region.
Other»
In addition, you will also need to allow access to the following:
- Your VCS provider.
- Any custom container registries if using custom runner images.
- Any other infrastructure required as part of your runs.
keys.openpgp.org, which is required to download the PGP key used to sign Spacelift binaries.
Hardware recommendations»
Hardware requirements for workers will vary depending on the stack size (how many resources managed, resource type, etc.), but we recommend:
- Memory: 2GB minimum
- Compute power: 2 vCPUs minimum
- Server types:
- AWS: t3.small instance type
- Azure: Standard_A2_V2 virtual machine
- GCP: e2-medium instance type
Using worker pools»
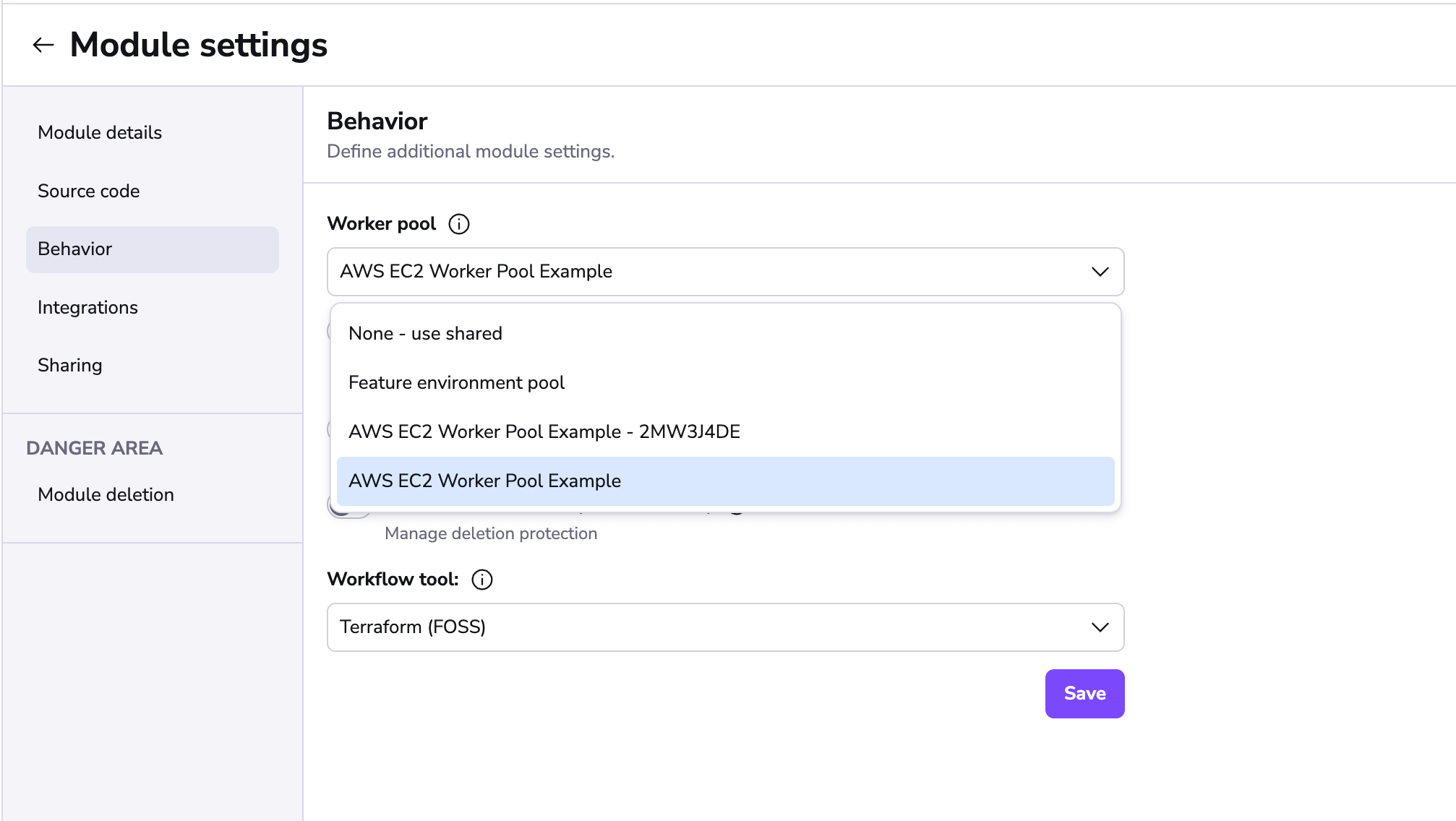
Worker pools must be explicitly attached to stacks and/or modules to process their workloads. This can be done in the Behavior section of stack and module settings:
Worker pool management views»
You can view the activity and status of every aspect of your worker pool in the worker pool detail view.
- Navigate to Manage Organization > Worker Pools.
- Click the name of the worker pool you'd like to manage or review.
- Use the tabs to navigate through the pool:
Private worker pool»
While Spacelift manages the workers in the public worker pool, you are responsible for managing the workers in a private worker pool.
Workers»
The Workers tab lists all workers for the worker pool and their statuses.
Status»
A worker can have one of three possible statuses:
DRAINED: The worker is not accepting new work.BUSY: The worker is currently processing or about to process a run.IDLE: The worker is available to start processing new runs.
Queue»
The Queue tab lists all runs that can be scheduled and are currently in progress. In-progress runs will be the first entries in the list without any filtering.
Info
A tracked run that is waiting on another tracked run, or a run that has a dependency on other runs might not show up in the queue.
Available Actions»
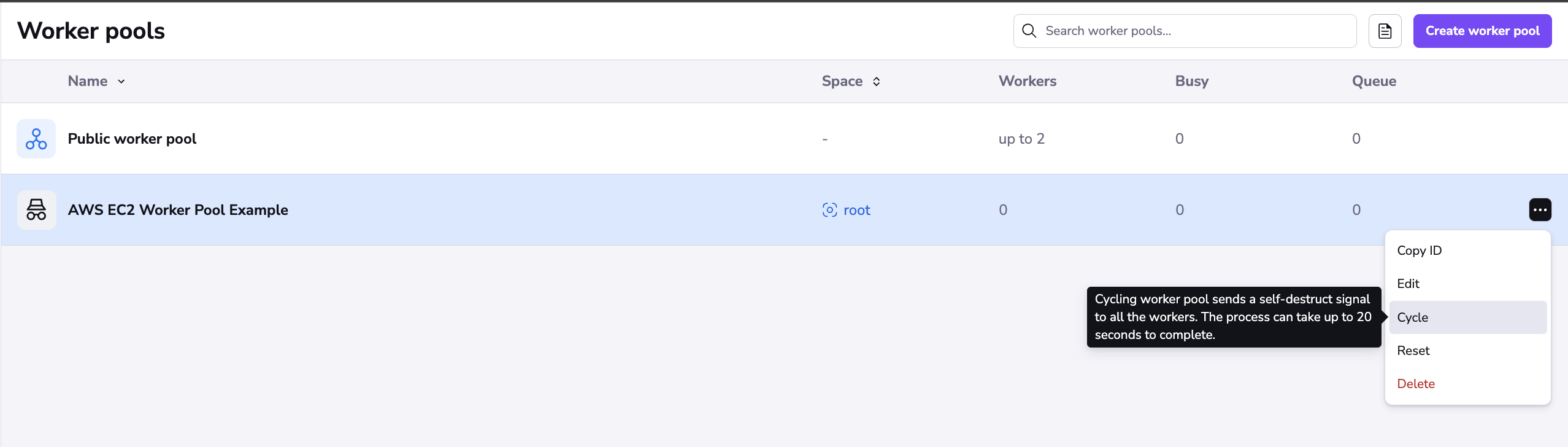
Cycle»
Cycling the worker pool sends a self-destruct signal to all the workers in this pool. The process can take up to 20 seconds to complete. When you click Cycle, you will be prompted to confirm this action as it cannot be undone.
Reset»
When you reset your worker pool, a new token is generated for your pool. Any workers using the old token will no longer be able to connect, so you will need to update the credentials for the workers connected to that pool.
You can use Reset to secure your workers if the certificate was compromised. Once your worker pool is reset, generate a new certificate.
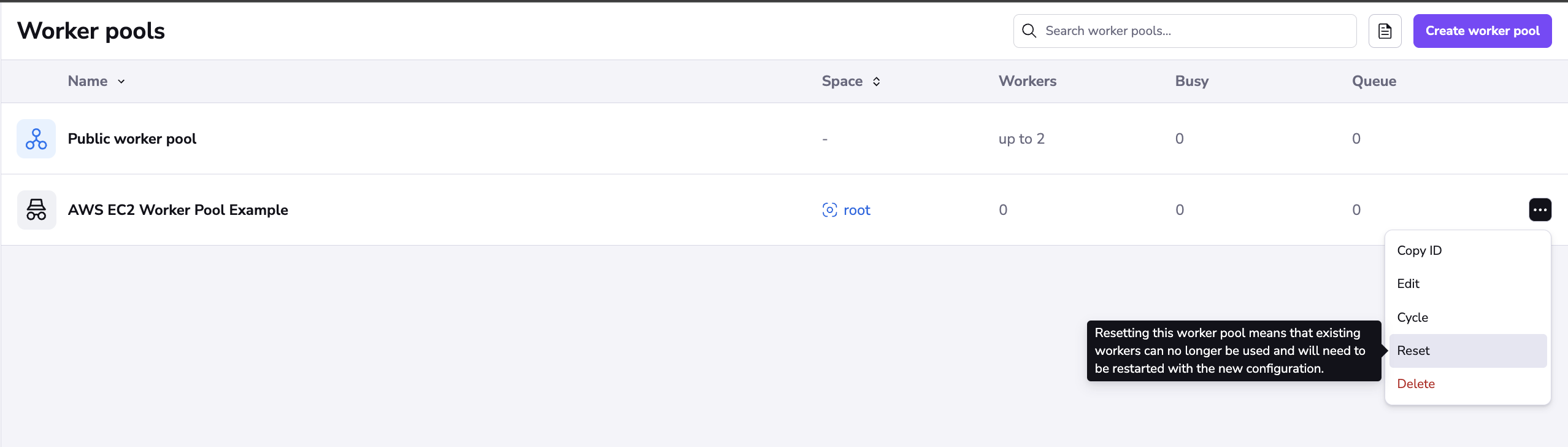
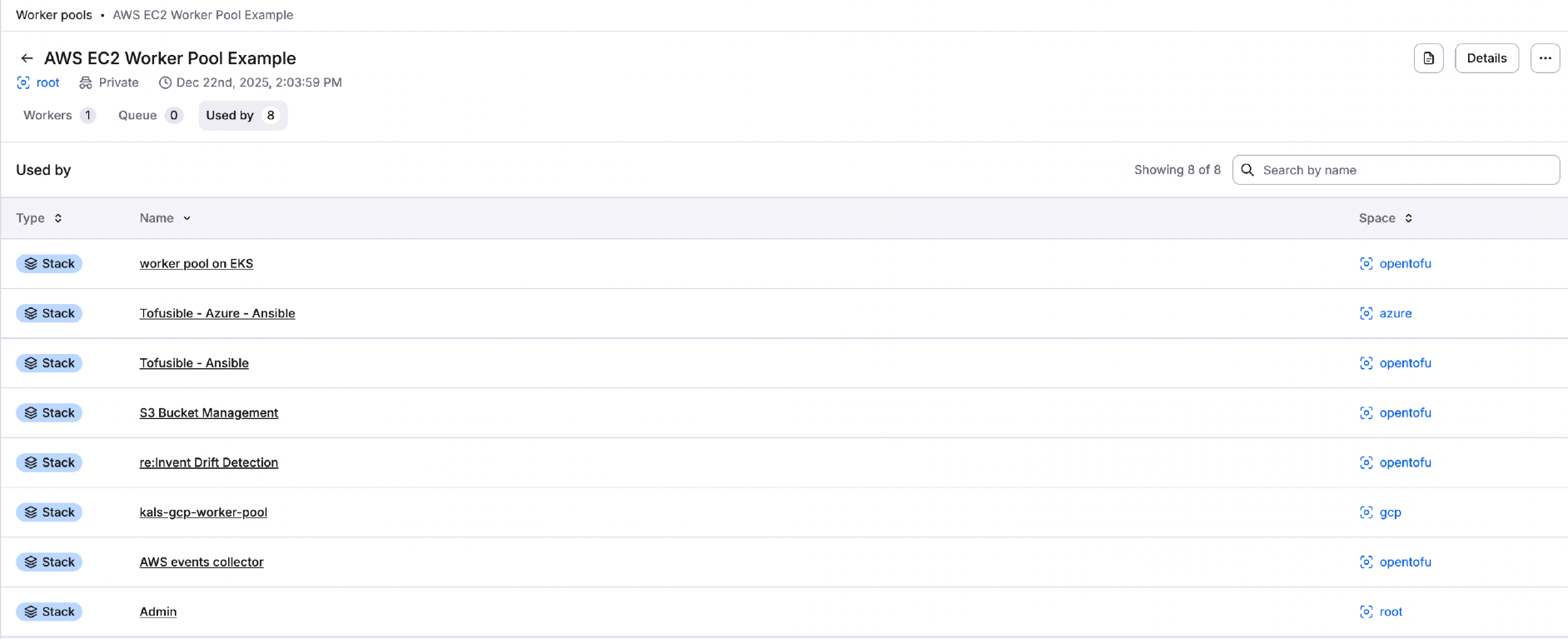
Used by»
The Used by tab lists all stacks and/or modules using the private worker pool.
Public worker pool»
The public worker pool is a worker pool managed by Spacelift. Due to security and compliance requirements, we do not list the workers of the public worker pool.
Queue»
The Queue tab lists all runs that can be scheduled and are currently in progress. In-progress runs will be the first entries in the list without any filtering.
Info
A tracked run that is waiting on another tracked run, or a run that has a dependency on other runs might not show up in the queue.
Used by»
The Used by tab lists all stacks and/or modules using the public worker pool.
Troubleshooting»
Spacelift doesn't show completed local runs»
Sometimes, the run completes locally in 10 minutes. But on Spacelift, it takes over 30 minutes, with no new activity appearing in the logs for the entire duration. If debug logging is on then the logs only show Still running... for that duration.
This issue might be related to the instance size and its CPU limitations. Monitor CPU and memory usage and make adjustments as needed.