Tracked run (deployment)»
Tracked runs represent the actual changes to your infrastructure caused by changes to your infrastructure definitions and/or configuration. In that sense, they can be also called deployments. Tracked runs are effectively an extension of proposed runs; instead of stopping at the planning phase, they also allow you to apply the previewed changes.
Tracked runs are presented on the Runs screen, which is the main screen of the Stack view:
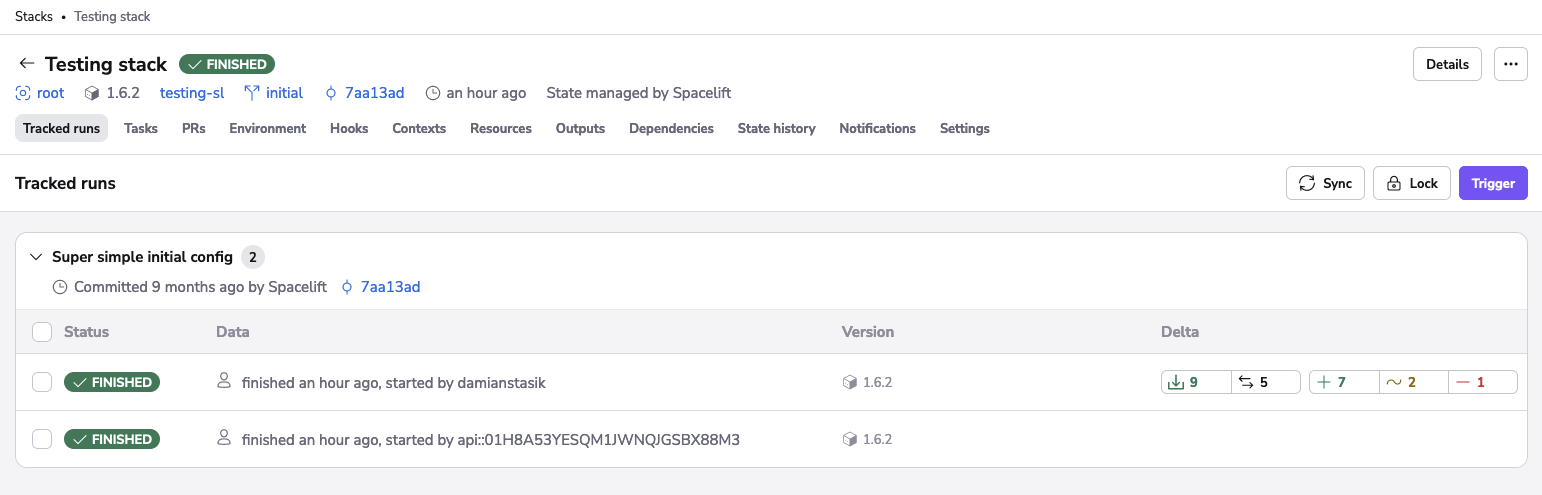
Each of the tracked runs is represented by a separate element containing some information about the attempted deployment:

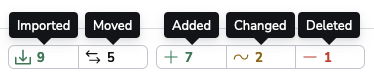
Additionally, if a tracked run also went through a successful planning phase, Spacelift displays a colorful delta counter representing the resources and outputs diff introduced by the change:
Triggering tracked runs»
Tracked runs can be triggered manually by the user, by a Git push, or by a trigger policy.
Triggering manually»
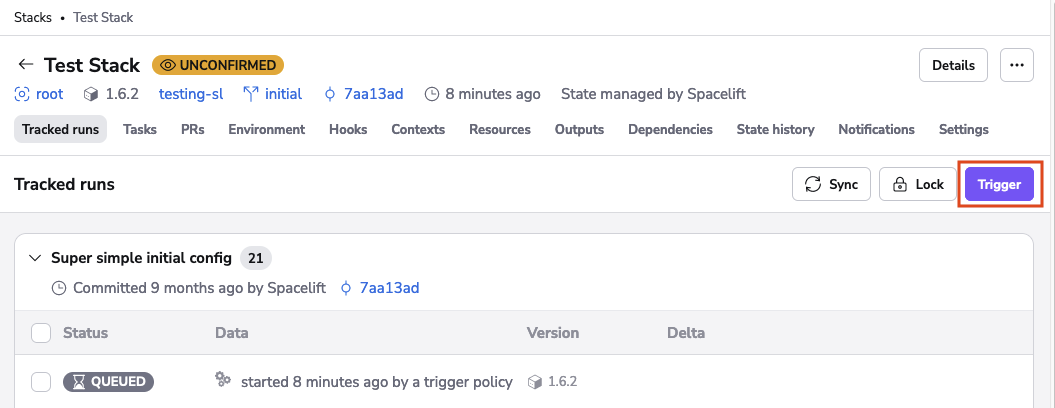
Any account admin or stack writer can trigger a tracked run on a stack:
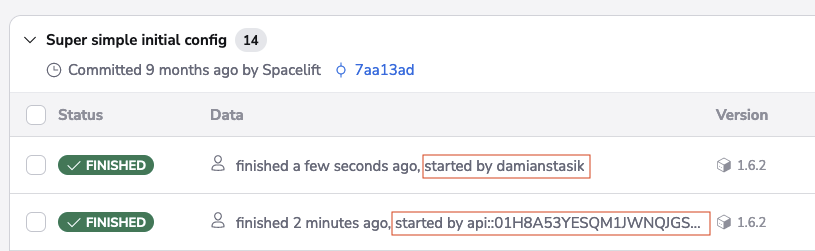
Runs triggered by individuals and machine users are marked accordingly:
Triggering runs with a custom runtime config»
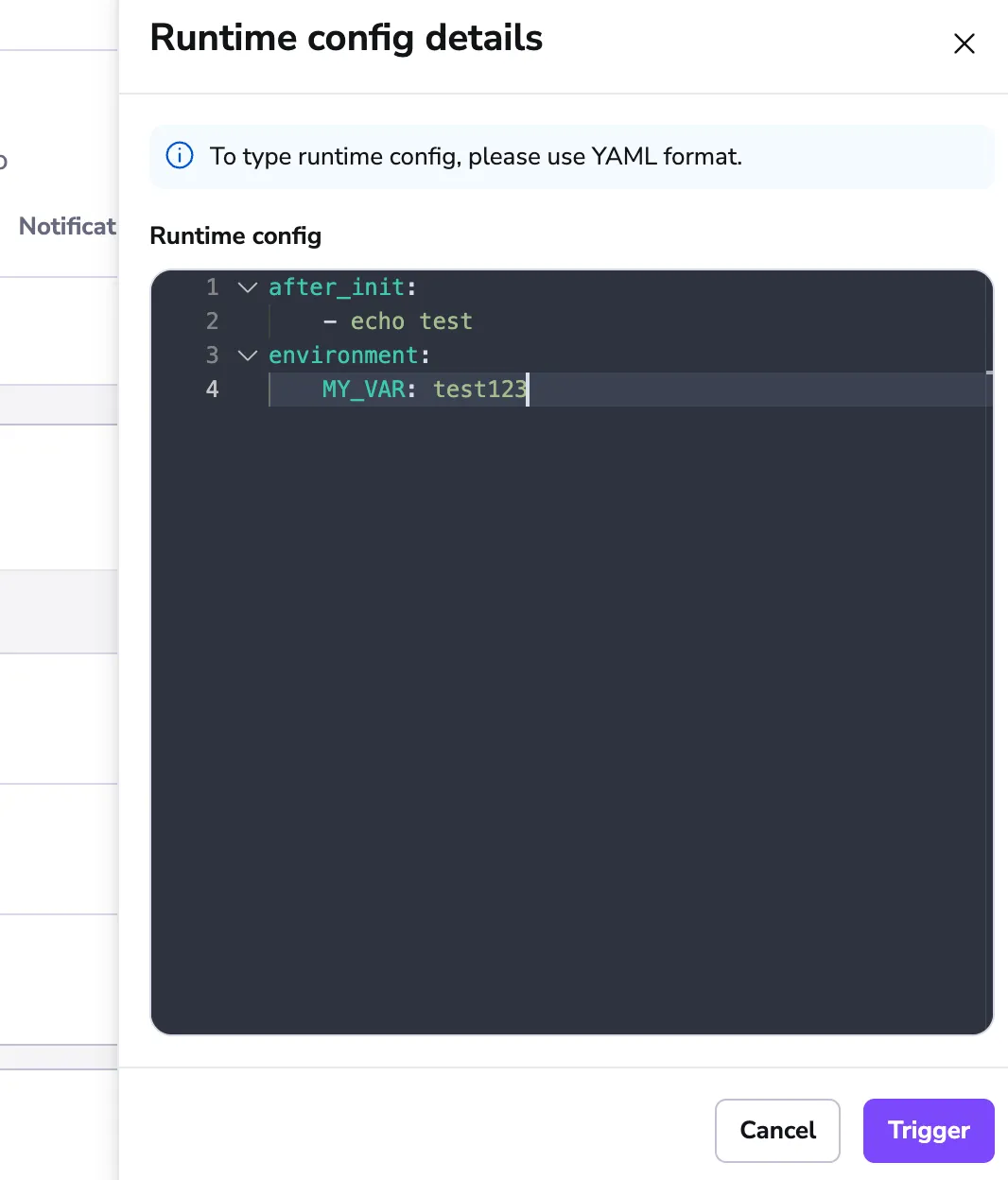
You can trigger runs with a custom runtime configuration to tailor the runtime environment to your specific needs at the moment of triggering a run.
The details of runtime config format can be found in the section about runtime YAML reference
Info
Triggering runs with custom runtime config is especially useful when last-mile configuration is needed.
Triggering from Git events»
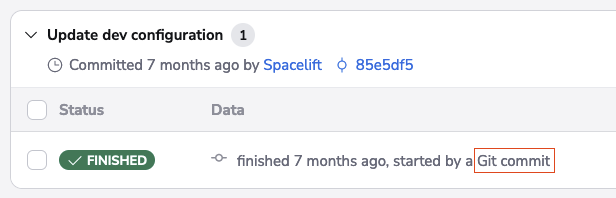
Tracked runs can also be triggered by Git push and tag events. By default, whenever a push occurs to the tracked branch, a tracked run is started for each of the affected stacks. This default behavior can be extensively customized using our push policies.
Runs triggered by Git push and/or tag events can are marked accordingly:
Triggering from policies»
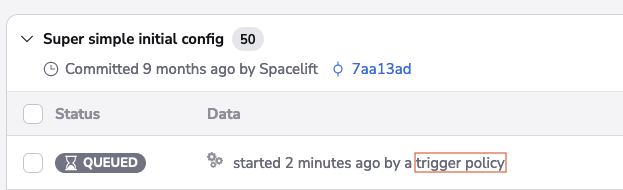
Trigger policies can create sophisticated workflows representing arbitrarily complex processes like staged rollouts or cascading updates. If a tracked run was triggered using policies, you will see this in the Spacelift UI:
Handling no-op changes»
If the planning phase detects no changes to the resources and outputs managed by the stack, the tracked run is considered a no-op. In that case it transitions directly from planning to finished state, just like a proposed run. Otherwise, it will go through the approval flow.
Approval flow»
If the tracked run detects a change to its managed resources or outputs, it goes through the approval flow. This can be automated or manual.
The automated flow involves a direct transition between the planning and applying phase, without an extra human intervention. This is a convenient but not always the safest option.
Changes can be automatically applied if both these conditions are met:
- Autodeploy is turned "on" for the stack.
- If plan policies are attached, none of them returns any warnings.
Otherwise, the change will go through the manual flow described below.
Unconfirmed»
If a change is detected and human approval is required, a tracked run will transition from the planning state to unconfirmed. At that point the worker node encrypts uploads the entire workspace to a dedicated Amazon S3 location and finishes its involvement with the run.
The resulting changes are shown to the user for the final approval:
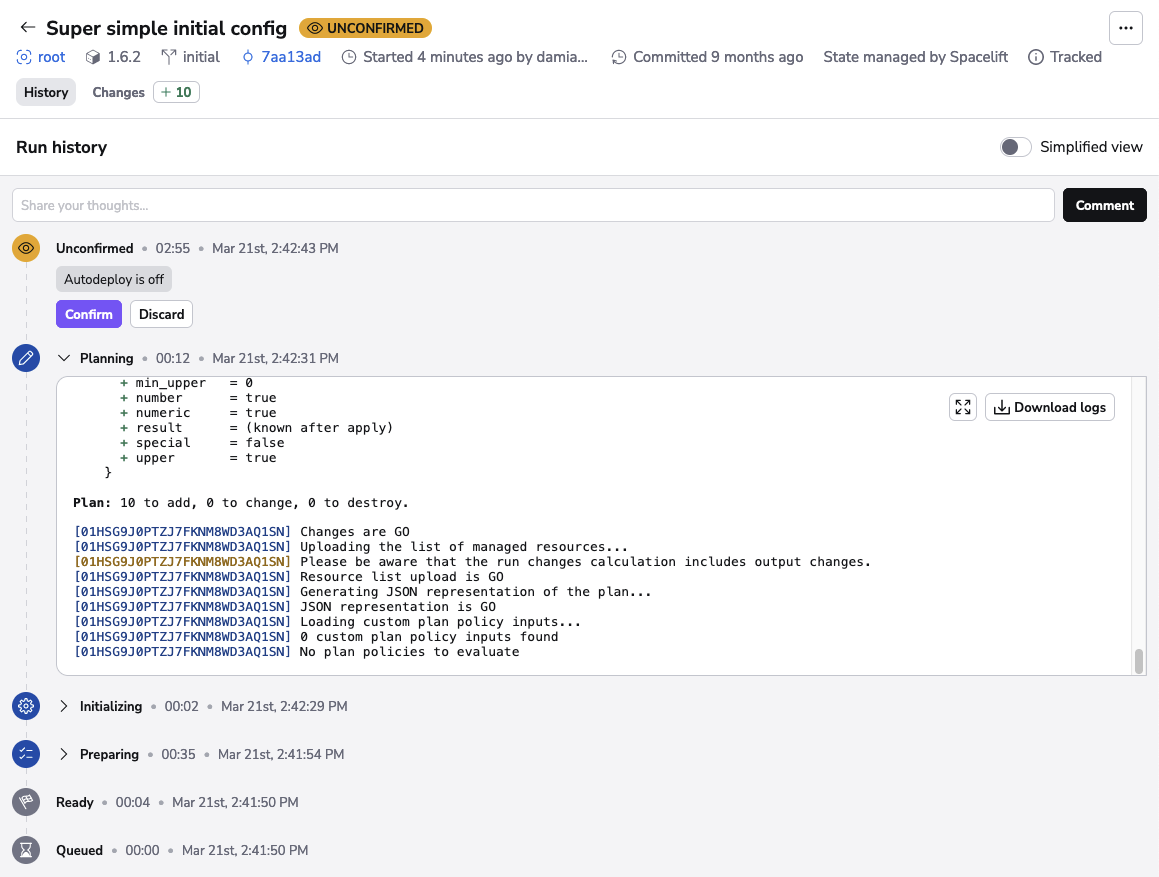
Unconfirmed is a passive state meaning no operations are performed while a run is in this state.
If the user approves (confirms) the plan, the run transitions to the confirmed state and waits for a worker node to pick it up. If the user doesn't like the plan and discards it, the run transitions to the terminal discarded state.
Targeted replan»
Info
This feature is only available to Business plan and above. Please check out our pricing page for more information.
When a run is in the unconfirmed state it's also possible to replan it. When replanning, a user is able to generate a new plan to apply by only picking specific changes from the current plan. This is similar to how passing the -target option to a OpenTofu/Terraform plan command works, without giving you the headache of writing the name of each resource you want to add to your targeted run.
To get to the replan screen after the run reaches the unconfirmed state, click on Changes in the left corner, select the resources you would like to have a targeted plan for, and then, the replan option will display.
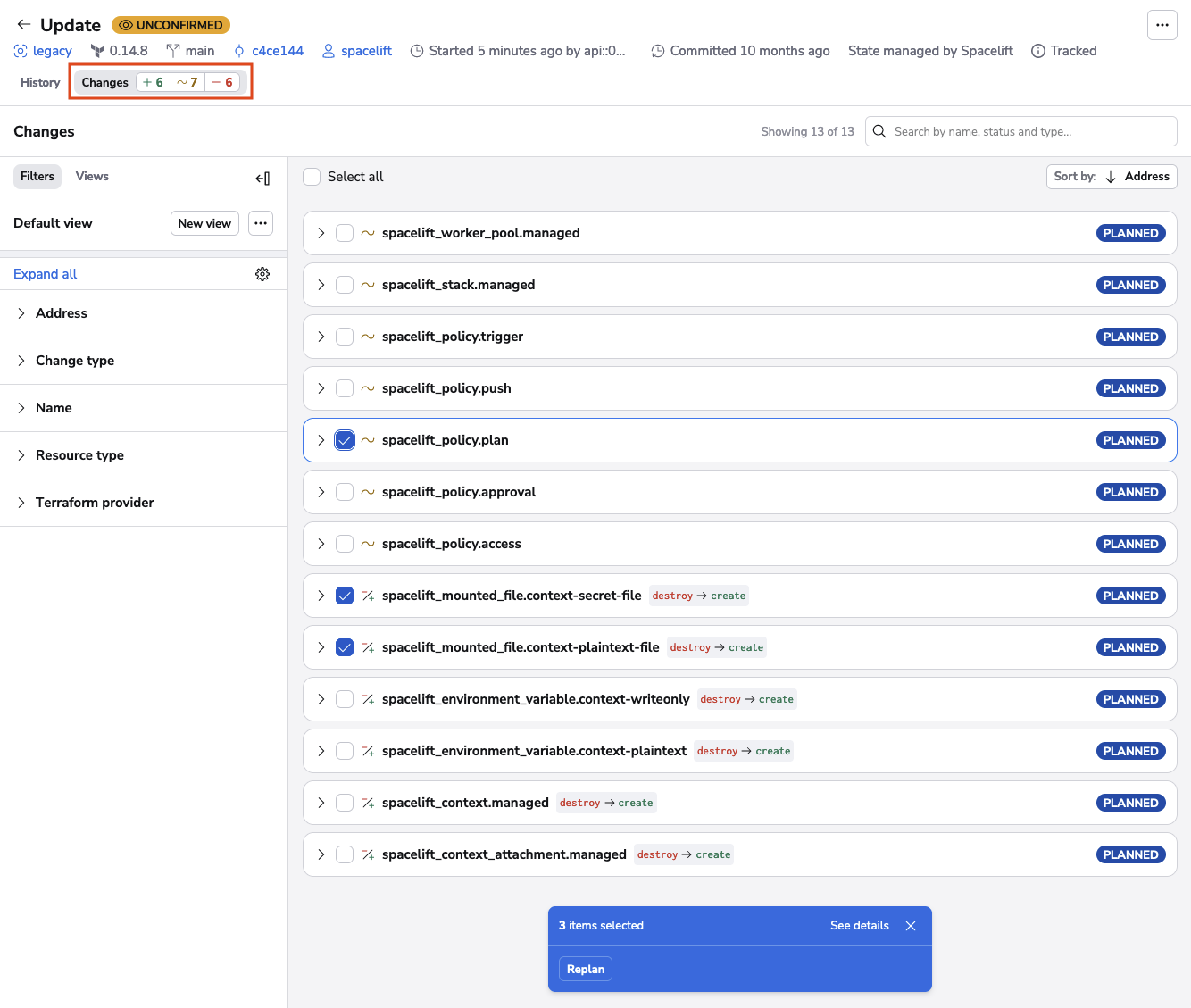
Discarded»
Discarded state follows unconfirmed and indicates that the user rejected the changes detected by the planning phase.
Discarded is a passive state, meaning no operations are performed. It's also a terminal state meaning that no further state can supersede it.
Confirmed»
Confirmed state follows unconfirmed and indicates that a user accepted the plan generated in the planning phase and wants to apply it, but no worker has picked up the job yet. This state is similar to queued in a sense that shows only temporarily until one of the workers picks up the associated job and changes the state to Applying. On the other hand, there is no way to stop a run once it's confirmed.
Confirmed is a passive state, meaning no operations are performed.
Applying»
If the run required a manual approval step, this phase is preceded by another handover (preparing phase) since the run again needs to be yielded to a worker node. This preparing phase is subtly different internally but ultimately serves the same purpose from the user perspective. Here's an example:
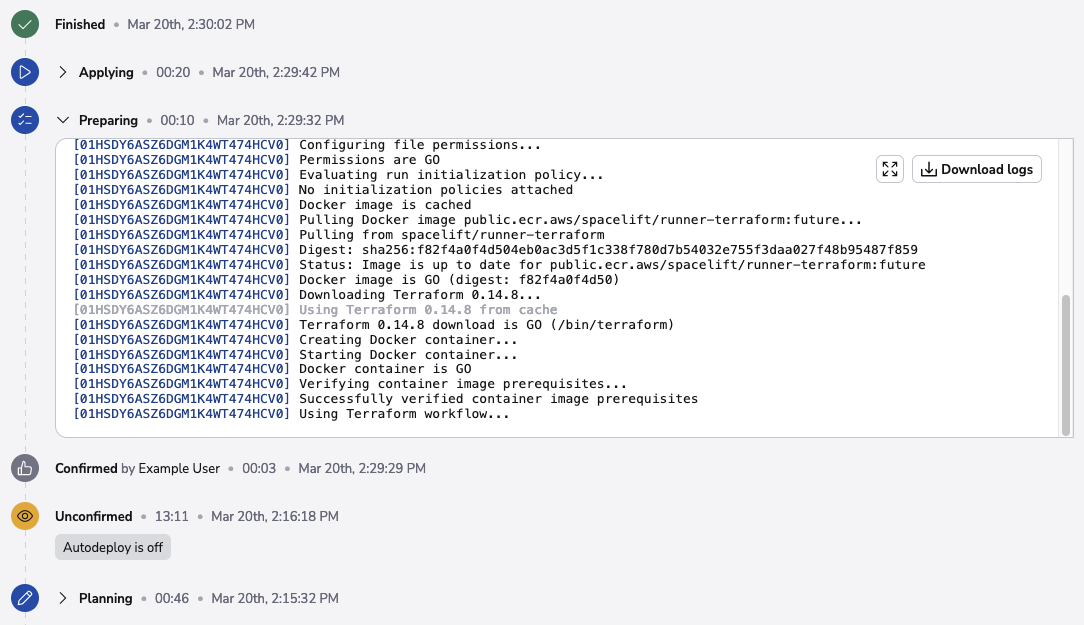
This preparation phase is very unlikely to fail, but if it does (e.g. the worker node becomes unavailable during the transition), the run will transition to the terminal failed state. If the handover succeeds, or the run does not go through the manual approval process, the applying phase begins and attempts to deploy the changes. Here's an example:
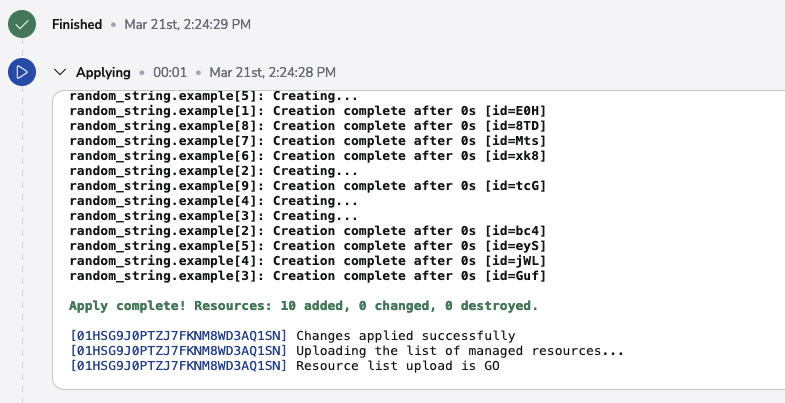
This phase can be skipped without execution by setting the SPACELIFT_SKIP_APPLYING environment variable to true in the stack's environment variables.
Success criteria»
If the run is a no-op or the applying phase succeeds, the run transitions to the finished state. On the other hand, if anything goes wrong, the run is marked as failed.
Reporting»
The results of tracked runs are reported in multiple ways:
- As deployments in VCS unless the change is a no-op. Refer to GitHub and GitLab documentation for the exact details.
- If configured, through Slack notifications.
- If configured, through webhooks.