Stack dependencies»
Stacks can depend on other stacks. This is useful when you want to run a stack only after another stack have finished running. For example, you might want to deploy a database stack before a stack that uses the database.
Info
Stack dependencies only respect tracked runs. Proposed runs and tasks are not considered.
Goals»
Stack dependencies aim to solve the problem of ordering the execution of related runs triggered by the same VCS event.
Stack dependencies do not manage stack lifecycle events such as creating or deleting stacks.
Defining stack dependencies»
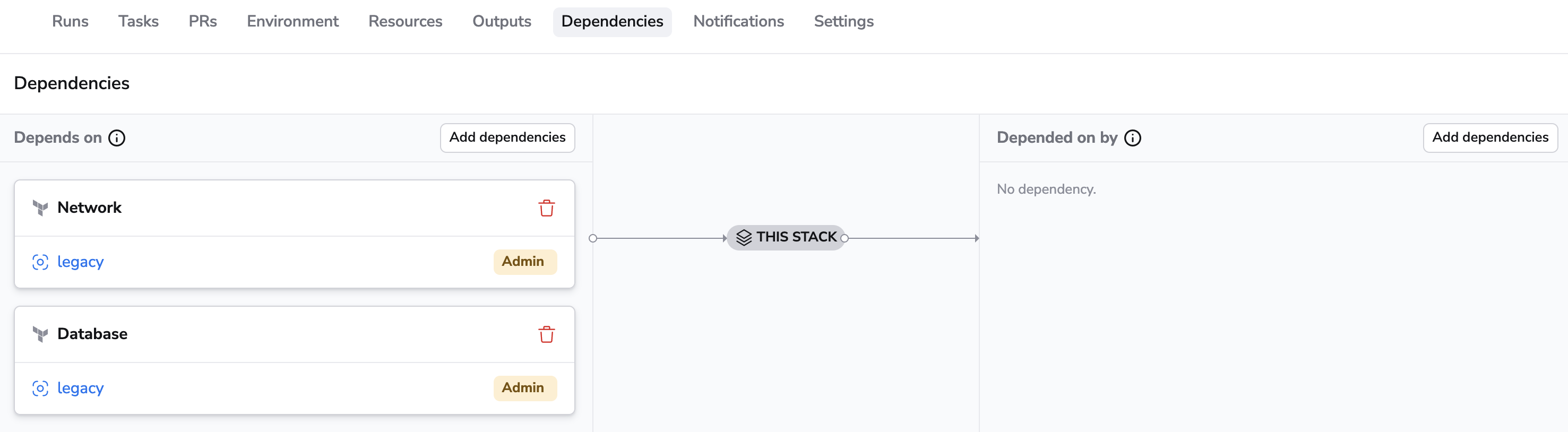
Stack dependencies can be defined in the Dependencies tab of the stack.
Info
In order to create a dependency between two stacks you need to have at least reader permission to one stack (dependency) and admin permission to the other (dependee). See Spaces Access Control for more information.
Defining references between stacks»
You have the option to refer to outputs of other stacks: by default, your stack will be only triggered if the referenced output has been created or changed. If you enable the Trigger always option however, the stack will be triggered regardless of the referenced output.
Note
Adding a new reference will always trigger a run. Removing one, however will not. If you want such behavior, consider enabling the Trigger always flag.
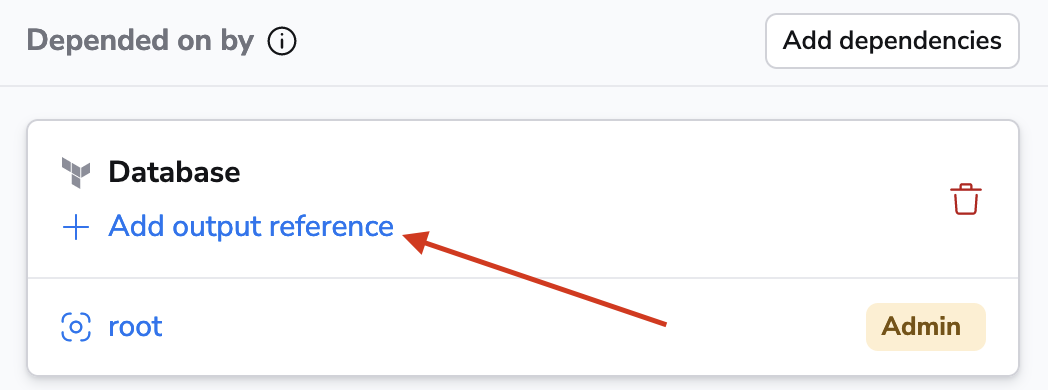
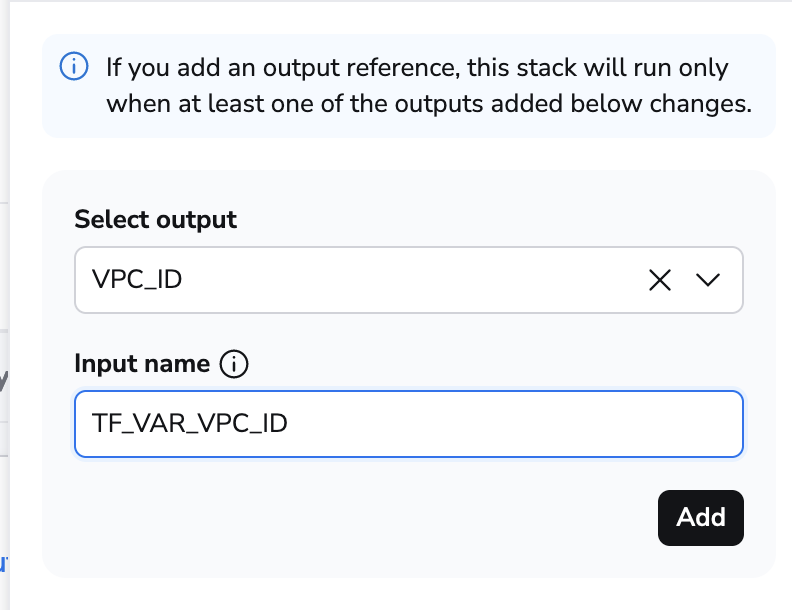
You can either choose an existing output value or add one that doesn't exist yet but will be created by the stack. On the receiving end, you need to choose an environment variable (Input name) to store the output value in.
Tip
If you use Terraform, make sure to use TF_VAR_ prefix for environment variable names.
Enabling sensitive outputs for references»
A stack output can be sensitive or non-sensitive. For example, in Terraform you can mark an output sensitive = true. Sensitive outputs are being masked in the Spacelift UI and in the logs.
In order for Spacelift to start uploading sensitive outputs to the server you need to enable it explicitly both on the Stack and on the Worker Pool level.
On the Stack level, you can enable it by setting the Transfer sensitive outputs across dependencies option to Enabled.

As for the worker pools it depends whether you are using public or private workers as this is enabled by default on our public worker pool.
On private worker pools however, it needs to be enabled explicitly by adding SPACELIFT_SENSITIVE_OUTPUT_UPLOAD_ENABLED=true environment variable to the worker. This is a requirement if you wish to utilize sensitive outputs for stack dependencies.
Stack dependency reference limitations»
When a stack has an upstream dependency with a reference, it relies on the existence of the outputs.
Note
We only use the outputs of a successful run. If the latest run of a stack has failed, the dependencies won't be able to use its outputs. A retry also does not trigger dependent stack/runs even if the retry is successful.
graph TD;
Storage --> |TF_VAR_AWS_S3_BUCKET_ARN|storageColor(StorageService);
style storageColor fill:#51cbadIf you trigger StorageService in the above scenario, Storage needs to have done a tracked run with an apply phase producing the output for TF_VAR_AWS_S3_BUCKET_ARN already. Otherwise you'll get the following error:
1 | |
Note
We have enabled the output uploading to our backend on 2023 August 21. This means that if you have a stack that produced an output before that date, you'll need to rerun it to make the output available for references.
We upload outputs during the Apply phase. If you stumble upon the error above, you'll need to make sure that the stack producing the output had a tracked run with an Apply phase.
The same applies if you have imported outputs into your stack, they also require an Apply phase in Spacelift. Outputs imported into a stack are only uploaded to the backend during this phase to be available for use as shared outputs. Without this step, the outputs will not propagate correctly.
You can simply do it by adding a dummy output to the stack and removing it afterwards:
1 2 3 | |
Note
If you are using CloudFormation - adding an output is considered a no-op, so if you are making an output-only change, you will need to make a modification to the Resources section of the CloudFormation template that is recognized as a change by CF - e.g adding a dummy resource like AWS::CloudFormation::WaitConditionHandle.
Reconciling failed runs»
When detecting changes in outputs, we also consider the previous run of the dependent stack. If the previous run wasn't successful, we'll trigger it regardless of the output changes. This is to ensure that the dependent stack has a chance to recover from a potential failure.
Vendor limitations»
Ansible and Kubernetes does not have the concept of outputs, so you cannot reference the outputs of them. They can be on the receiving end though:
graph TD;
A[Terraform Stack] --> |VARIABLE_1|B[Kubernetes Stack];
A --> |VARIABLE_2|C[Ansible Stack];Scenario 1»
graph TD;
Infrastructure --> |TF_VAR_VPC_ID|Database;
Database --> |TF_VAR_CONNECTION_STRING|PaymentService;In case your Infrastructure stack has a VPC_ID, you can set that as an input to your Database stack (e.g. TF_VAR_VPC_ID). When the Infrastructure stack finishes running, the Database stack will be triggered and the TF_VAR_VPC_ID environment variable will be set to the value of the VPC_ID output of the Infrastructure stack.
If there is one or more references defined, the stack will only be triggered if the referenced output has been created or changed. If they remain the same, the downstream stack will be skipped. You can control this behavior by enabling or disabling the Trigger always option.
Scenario 2»
graph TD;
Infrastructure --> |TF_VAR_VPC_ID|Database;
Database --> |TF_VAR_CONNECTION_STRING|PaymentService;
Database --> CartService;You can also mix references and referenceless dependencies. In the above case, CartService will be triggered whenever Database finishes running, regardless of the TF_VAR_CONNECTION_STRING output.
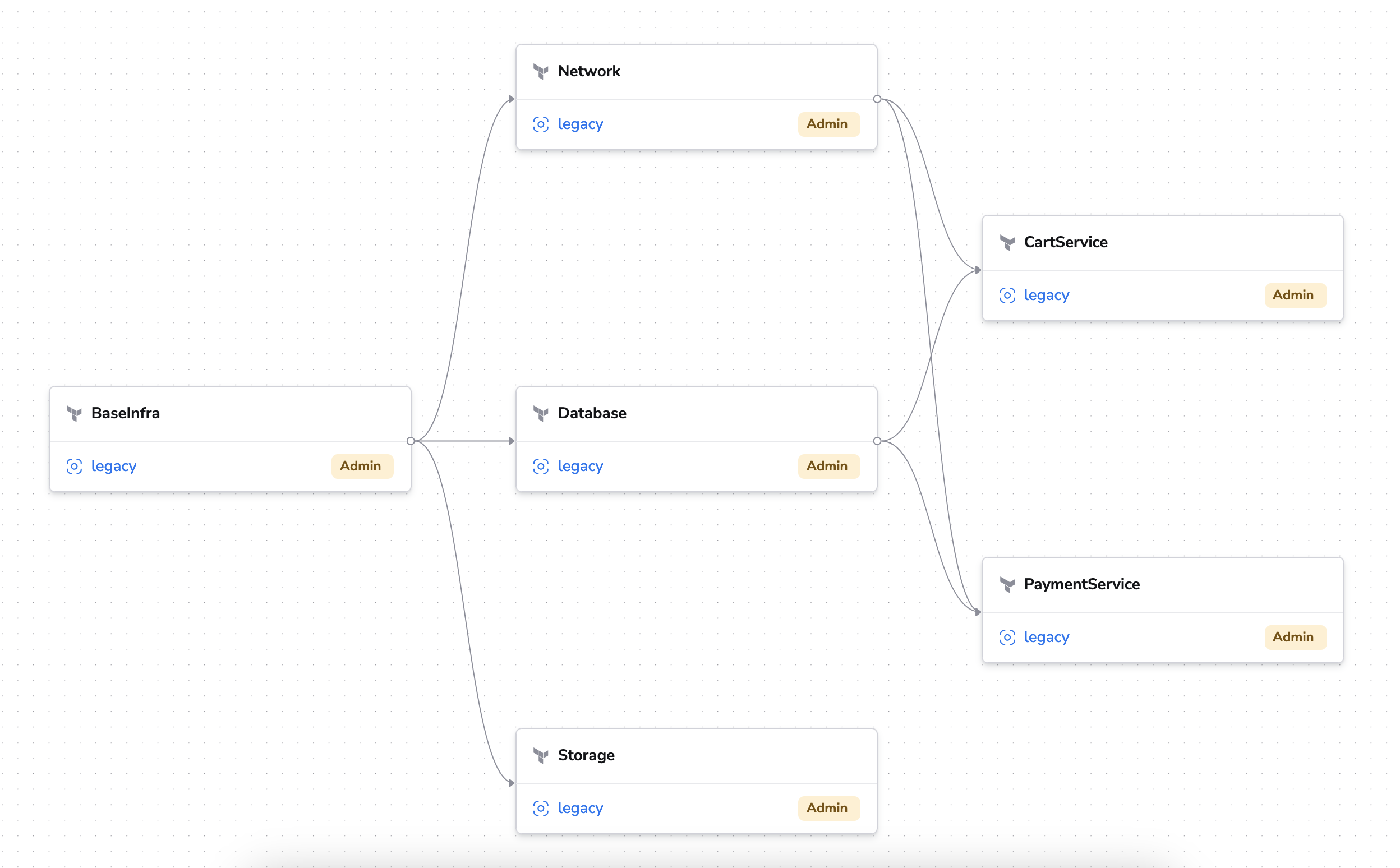
Dependencies overview»
In the Dependencies tab of the stack, there is a button called Dependencies graph to view the full dependency graph of the stack.
How it works»
Stack dependencies are directed acyclic graphs (DAGs). This means that a stack can depend on multiple stacks, and a stack can be depended on by multiple stacks but there cannot be loops: you will receive an error if you try to add a stack to a dependency graph that will create a cycle.
When a tracked run is created in the stack (either triggered manually or by a VCS event), and the stack is a dependency of other stack(s), those stacks will queue up tracked runs and wait until the current stack's tracked run has finished running.
If a run fails in the dependency chain, all subsequent runs will be cancelled.
It will be easier to understand in a second.
Examples»
Scenario 1»
graph TD;
BaseInfra-->Database;
BaseInfra-->networkColor(Network);
BaseInfra-->Storage;
Database-->paymentSvcColor(PaymentService);
networkColor(Network)-->paymentSvcColor(PaymentService);
Database-->cartSvcColor(CartService);
networkColor(Network)-->cartSvcColor(CartService);
style networkColor fill:#51cbad
style paymentSvcColor fill:#51abcb
style cartSvcColor fill:#51abcbIn the above example, if Network stack receives a push event to the tracked branch, it will start a run
immediately and queue up PaymentService and CartService. When Network finishes running,
those two will start running. Since PaymentService and CartService does not depend on each other,
they can run in parallel.
BaseInfra remains untouched, we never go up in the dependency graph.
Scenario 2»
graph TD;
baseInfraColor(BaseInfra)-->databaseColor(Database);
baseInfraColor(BaseInfra)-->networkColor(Network);
baseInfraColor(BaseInfra)-->storageColor(Storage);
databaseColor(Database)-->|TF_VAR_CONNECTION_STRING|paymentSvcColor(PaymentService);
networkColor(Network)-->paymentSvcColor(PaymentService);
databaseColor(Database)-->cartSvcColor(CartService);
networkColor(Network)-->cartSvcColor(CartService);
style baseInfraColor fill:#51cbad
style networkColor fill:#51abcb
style paymentSvcColor fill:#51abcb
style cartSvcColor fill:#51abcb
style storageColor fill:#51abcb
style databaseColor fill:#51abcbIf BaseInfra receives a push event, it will start running immediately and queue up
all of the stacks below. The order of the runs: BaseInfra, then Database & Network & Storage in parallel,
finally PaymentService & CartService in parallel.
Since PaymentService and CartService does not depend on Storage, they will not
wait until it finishes running.
Note: PaymentService references Database with TF_VAR_CONNECTION_STRING. But since it also depends on Network with no references, it'll run regardless of the TF_VAR_CONNECTION_STRING output. If the Database stack does not have the corresponding output, the TF_VAR_CONNECTION_STRING environment variable will not be injected into the run.
Scenario 3»
graph TD;
baseInfraColor(BaseInfra)-->databaseColor(Database);
baseInfraColor(BaseInfra)-->networkColor(Network);
baseInfraColor(BaseInfra)-->storageColor(Storage);
databaseColor(Database)-->paymentSvcColor(PaymentService);
networkColor(Network)-->paymentSvcColor(PaymentService);
databaseColor(Database)-->cartSvcColor(CartService);
networkColor(Network)-->cartSvcColor(CartService);
style baseInfraColor fill:#51cbad
style networkColor fill:#e21316
style paymentSvcColor fill:#ecd309
style cartSvcColor fill:#ecd309
style storageColor fill:#51abcb
style databaseColor fill:#51abcbIn this scenario, similarly to the previous one BaseInfra received a push,
started running and queued up all of the stacks below. However, Network stack
has failed which means that the rest of the runs (PaymentService and CartService) will
be skipped.
Same level stacks (Database & Storage) are not affected by the failure.
Scenario 4»
graph TD;
baseInfraColor(BaseInfra)-->databaseColor(Database);
baseInfraColor(BaseInfra)-->networkColor(Network);
baseInfraColor(BaseInfra)-->storageColor(Storage);
databaseColor(Database)-->paymentSvcColor(PaymentService);
networkColor(Network)-->paymentSvcColor(PaymentService);
databaseColor(Database)-->cartSvcColor(CartService);
networkColor(Network)-->cartSvcColor(CartService);
style baseInfraColor fill:#51cbad
style networkColor fill:#51cbad
style paymentSvcColor fill:#51abcb
style cartSvcColor fill:#51abcb
style storageColor fill:#51cbad
style databaseColor fill:#51cbadLet's assume that the infrastructure (BaseInfra, Database, Network and Storage) is a monorepo, and a push event affects all 4 stacks.
The situation isn't any different than Scenario 2. The dependencies are still respected and the stacks will run in the proper order: BaseInfra first, then Database & Network & Storage in parallel, finally PaymentService & CartService in parallel.
Scenario 5»
graph TD;
baseInfraColor(BaseInfra)-->databaseColor(Database);
baseInfraColor(BaseInfra)-->networkColor(Network);
baseInfraColor(BaseInfra)-->storageColor(Storage);
databaseColor(Database)-->paymentSvcColor(PaymentService);
networkColor(Network)-->paymentSvcColor(PaymentService);
databaseColor(Database)-->cartSvcColor(CartService);
networkColor(Network)-->cartSvcColor(CartService);
storageColor(Storage)-->|TF_VAR_AWS_S3_BUCKET_ARN|storageSvcColor(StorageService);
style baseInfraColor fill:#51cbad
style networkColor fill:#51abcb
style paymentSvcColor fill:#51abcb
style cartSvcColor fill:#51abcb
style storageColor fill:#51abcb
style databaseColor fill:#51cbad
style storageSvcColor fill:#ecd309If BaseInfra and Database are a monorepo and a push event affects both of them, this scenario isn't any different than Scenario 2 and Scenario 4. The order from top to bottom is still the same: BaseInfra first, then Database & Network & Storage in parallel, finally PaymentService & CartService in parallel.
Storage and StorageService: let's say that the S3 bucket resource of Storage already exists. This means that the bucket ARN didn't change, so StorageService will be skipped.
Trigger policies»
Stack dependencies are a simpler alternative to Trigger policies that cover most use cases. If your use case does not fit Stack dependencies, consider using a Trigger policy.
There is no connection between the two features, and the two shouldn't be combined to avoid confusion or even infinite loops in the dependency graph.
Stack deletion»
A stack cannot be deleted if it has downstream dependencies (child stacks depending on it). If you want to delete such a stack, you need to delete all of its downstream dependencies first. However, if a stack only has upstream dependencies (parent stacks that it depends on), it can be deleted without any issues.
Ordered Stack creation and deletion»
As mentioned earlier, Stack Dependencies do not aim to handle the lifecycle of the stacks.
Ordering the creation and deletion of stacks in a specific order is not impossible though. If you manage your Spacelift stacks with the Spacelift Terraform Provider, you can easily do it by setting spacelift_stack_destructor resources and setting the depends_on Terraform attribute on them.
Here is a simple example of creating a dependency between 3 stacks and setting up a destructor for them. By setting up a destructor resource with the proper depends_on attribute, it ensures that the deletion of the stacks will happen in the proper order. First child, then parent. This is also an easy way to create short-lived environments.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 | |
What happens during terraform apply:
- Terraform creates the 3 stacks
- Sets up the dependency between them
You might notice the three destructors at the end. They don't do anything yet, but they will be used during terraform destroy. Destroy order:
- Terraform destroys the dependencies and dependency references
- Destroys the grandchild stack (
app) and its resources - Destroys the parent stack (
infra) and its resources - Finally, destroys the grandparent stack (
vpc) and its resources
Troubleshooting»
Error: job assignment failed: the following inputs are missing»
This error occurs when the outputs were not part of an apply phase in Spacelift, this includes if the outputs are available in your state file and visible under the Outputs tab. For the output references to be available, the outputs need to have been part of a tracked run with an apply phase. You can read more about this here.
Error: argument list too long»
If you're adding a large number of data sources to the parent stack and pushing them as an output you might get an error like this:
1 | |
This is because one cannot have more than 128kB in any given argument. This is hard-coded in the kernel and difficult to work around.
Depending on your use case it may be possible to work around this issue by using the Spacelift Terraform Provider resources spacelift_mounted_file along with spacelift_run.